
Abstract
The current investigation addresses the pressing need to integrate orphan or underutilized crops into mainstream agriculture, focusing on Perilla (Perilla frutescens L.) due to its superior nutritional profile. A major challenge is the lack of fast, cost-effective, and labor-efficient screening methods for germplasm. Near-Infrared Reflectance Spectroscopy (NIRS) addresses this by providing precise and rapid determination of crucial biochemical parameters. This study developed Modified Partial Least Squares (mPLS) regression-based NIRS prediction models using WinISI and 1D Convolutional Neural Networks (CNN) to enable high-throughput screening for moisture, ash, proteins, total soluble sugars (TSS), and phenols in Perilla germplasm. Calibration with WinISI involved mathematical treatments, optimizing for each trait: “2,6,6,1” for moisture, “3,4,4,1” for ash and TSS, “3,4,6,1” for protein, and “2,4,6,1” for phenols. The 1D CNN model, with lower mean absolute error (MAE), was further validated. External validation metrics, including RSQexternal, SEP(C), slope, bias, and RPD, assessed prediction accuracy. Comparative evaluation showed WinISI performed better for moisture prediction, while the 1D CNN model excelled in predicting ash, protein, TSS, and total phenol, highlighting the importance of model selection for specific traits. This rapid screening tool aids in identifying nutritionally dense Perilla genotypes, guiding targeted breeding efforts, and represents the first comparative mPLS and DL-based modeling using NIRS data for Perilla.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The North Eastern Himalayan region (NEHR) of India is endowed with a remarkable biodiversity, particularly concerning potential, underutilized, and orphan crops. Among these, Perilla (Perilla frutescens L.) also known as shiso, egoma, Kkaennip, suzi, or beefsteak plant is used in culinary applications such as garnishes, flavoring agents, and in pickling in NEHR of India. It also has medicinal uses, including anti-inflammatory, anti-hyperglycemic, and anti-allergic treatments, with derived products like perilla oil and perilla seed powder being used in food and health supplements [8]. Cultivation of perilla in the NEH region, particularly in states like Arunachal Pradesh, Manipur, Nagaland, Meghalaya, and Sikkim, is important for enhancing nutritional diversity, preserving traditional practices, and uplifting economic opportunities [2]. Notably, Perilla seeds exhibit a protein content ranging from 15.7% to 23.9%, predominantly concentrated in the seed kernel, exceeding conventional oil sources like mustard, cotton, linseed, sunflower, coconut, and almond in quality and quantity. Moreover, Perilla seeds have a total phenol content (TPC) of approximately 18.00 mg GAE/g oil extract, with abundance of rosmarinic acid, rosmarinic acid-3-O-glucoside, caffeic acid, ferulic acid, and caffeic acid-3-O-glucoside [8, 19, 22].
The balanced complementary composition of proteins and phenols in Perilla seeds renders them a promising candidate for functional foods. In food storage and processing, the intrinsic interaction between proteins and phenols plays a crucial role, with the oxidation of hydroxyl groups to quinones followed by bonding to nucleophilic groups of proteins being fundamental to this interaction. Utilizing this interaction in constructing emulsion delivery systems has shown promise in enhancing the structure and properties of proteins [9]. Recent studies have demonstrated the successful covalent modification of Perilla seed meal protein with polyphenols, resulting in enhanced solubility and potential applications as stabilizers in innovative emulsification systems [39].
Given the importance of Perilla genotypes with dense nutritional profiles for functional foods, selection based on balanced compositions of proteins, phenols, and other relevant components such as moisture and TSS is imperative. Near-infrared reflectance spectroscopy (NIRS)-based modeling plays a crucial role in analyzing the nutritional profile of diverse crop germplasm, owing to its rapid analysis, non-destructive nature, cost-effectiveness, and ability to predict multiple biochemical traits simultaneously [37]. This methodology exploits the interaction between near-infrared light and matter within the electromagnetic radiation spectrum spanning from 780 to 2500 nm [23]. Deep learning (DL) models such as convolutional neural networks (CNNs) exhibit significant utility in predicting nutrient contents using NIR spectra and reference values generated in laboratories, owing to their ability to capture complex hidden patterns in high-dimensional data [32].
Despite regression-based NIRS prediction models being employed for various biochemical constituents in diverse crops [3, 17, 28, 38], there is a scarcity of similar reports in Perilla. The present study aims to bridge this gap by predicting accurate relationships between these biochemical traits and spectral information through Modified Partial Least Squares (MPLS) using WinISI and 1D CNN. We developed and validated 10 NIRS-based prediction models for five biochemical traits employing both WinISI and 1D CNN approaches. Comparative chemometrics and statistical approaches were employed to confirm the robustness of the developed models, ensuring a rigorous evaluation of their effectiveness and reliability in predicting these biochemical constituents. This pioneering NIRS-based study offers insights into the biochemical constituents of Perilla germplasm collection in the NEHR of India, laying the foundation for future scientific investigations and advancing strategies for sustainable agriculture and biodiversity conservation. The developed models hold promise for the rapid screening of biochemically rich genotypes or landraces, facilitating their integration into suitable areas and contributing to the development of advanced breeding strategies targeting nutritionally rich genotypes for food and feed.
Materials and methods
Plant materials
A total of 90 genotypes of Perilla were collected from various locations across the NEH region of India and grown for three consecutive kharif seasons (June – October) from 2021 to 2023. The plants were cultivated in an augmented design with seven blocks and three checks at the upland experimental farm of the Division of Crop Science, ICAR-Research Complex for NEH Region, Umiam, Meghalaya, India. Each block measured 3.5 m × 3.0 m with a spacing of 50.0 cm × 35.0 cm. Standard agronomic practices were followed throughout the crop season. Seeds were harvested at physiological maturity, sun-dried, then dried in a hot air oven at 60 °C overnight. The cleaned seeds were stored in conical polypropylene falcon tubes for subsequent laboratory analyses.
Quantification of biochemical parameters
The quantification of moisture, ash, protein, TSS, and total phenol content (TPC) was performed using appropriately dried perilla seeds. The detailed procedure for estimating these parameters is outlined in the following subsections.
Moisture and ash content
Empty quartz crucibles were conditioned in a muffle furnace, set at 110.0 °C, for more than 1 h until they achieved a constant weight. Subsequently, Perilla seed samples, precisely measured to 0.5 g, were transferred into these pre-weighed quartz crucibles. Following this:
-
The crucibles containing the samples were subjected to a 12-h heat treatment at 110.0 °C. Upon completion of the heat treatment, the crucibles were reweighed to determine any weight changes.
-
To ensure thorough desiccation, the crucibles were once again placed in the muffle furnace at 110 °C for an additional 4 h, confirming the attainment of a constant weight.
-
The difference between the initial weight of the crucibles and the weight after drying represented the moisture content of the samples and was expressed as a percentage of the initial weight (g/100 g).
-
Subsequently, the same set of crucibles was heated for 16 h, during which the furnace temperature gradually increased from 110 °C to 450 °C. Following this process, the crucibles were weighed twice more to ensure consistency in weight. The weight of the resulting ash was determined as a percentage of the initial sample weight (g/100 g) [35].
Protein content
The estimation of protein content in properly dried Perilla seeds was conducted using the Dumas combustion method.
-
This method entails subjecting the sample to combustion at elevated temperatures, typically around 900 °C. During combustion, nitrogen present in the sample is converted into nitrogen gas (N2), which can be detected using a thermal conductivity detector.
-
The combustion process occurs in the presence of excess oxygen, ensuring quantitative digestion of the sample and allowing for accurate determination of its total nitrogen concentration. Gases produced during combustion, including CO2, H2O, and N2, are directed through specialized columns containing aqueous KOH. These columns absorb CO2 and H2O, leaving behind N2.
-
The remaining N2 is then separated from any residual CO2 and H2O by a column equipped with a thermal conductivity detector (TCD). The TCD signal, along with the sample weight, is analyzed by a connected PC using the Dumas method to calculate the total nitrogen concentration in the samples.
-
The total protein content is determined in triplicate by multiplying the measured nitrogen quantity by a conversion factor of 6.25 and expressing the result as a percentage. The calculation is as follows:
$$Crude\,protein(\% ) = \frac{{Nitrogen\,content\,(g) \times 6.25}}{{Sample\,weight\,(g)}}$$(1)
Preparation of extracts (supernatant) for TSS and total phenol estimation
Triplicate samples of homogenized Perilla seeds, each weighing 100 mg, were transferred into screw-capped falcon tubes. Subsequently, 5 mL of 80% ethanol was added to each tube, followed by thorough vortexing for 2–3 min to ensure thorough mixing. The tubes were then left undisturbed overnight to allow for efficient extraction. The following day, the falcon tubes were immersed in a water bath set at 80 °C for 30 min. After cooling to room temperature, the tubes were placed on a rotator for 75 min to facilitate further extraction. Subsequently, the tubes were centrifuged at 15,000 g for 10 min. The supernatant, containing extracted compounds, was collected and subjected to two additional extraction cycles using the same protocol to ensure complete extraction. The combined supernatant from all cycles was carefully transferred into fresh falcon tubes, and the final volume was adjusted to 10 mL. The resulting supernatant was used for estimating both total soluble sugars (TSS) and total phenolic content in the Perilla seed samples.
Total soluble sugars (TSS)
The determination of total soluble sugars (TSS) was conducted following the method proposed by Hansen and Møller [14], with slight modifications.
-
Triplicates of 200 μL of prepared extracts (as described in the preceding section) were carefully dispensed into test tubes and evaporated completely over a water bath at 100 °C. Subsequently, 1 mL of double-distilled water was added to each test tube and vigorously vortexed to ensure proper dissolution.
-
Concurrently, separate tubes were prepared as blanks by adding 1 mL of double-distilled water. For the preparation of standards, varying amounts (ranging from 0.01 to 0.1 mg) of d-glucose were added to separate tubes, and the volume was adjusted to 1 mL with double-distilled water. Following this, 4 mL of ice-cold anthrone reagent was added to three sets of test tubes containing samples, blanks, and standards.
-
The tubes were then incubated in a water bath at 80 °C for 8 min. During incubation, the sulfuric acid present in the anthrone reagent dehydrates the carbohydrates, leading to the production of furfural. Subsequently, anthrone reacts with furfural, resulting in the formation of a characteristic green–blue coloration that can be quantified using spectrophotometry.
-
The absorbance of each solution was measured at 630 nm against the blank. The concentration of total soluble sugars was then determined and expressed as g/100 g dry weight. Quantification was performed using a d-glucose standard curve, allowing for accurate estimation of TSS content in the Perilla seed samples.
Total phenols
Total phenols were quantified following the methodology outlined by Tian et al. [37] with minor modifications.
-
Triplicate aliquots of 500 μL each of the pre-prepared extract (as described in the preceding section) were evaporated at 100 °C over a water bath and subsequently reconstituted with 3 mL of double-distilled water (DDW), followed by vigorous vortexing.
-
Concurrently, a blank was prepared by adding 3.0 mL of DDW to separate tubes. For the preparation of standards, gallic acid (GA) in varying concentrations ranging from 0.01 to 0.05 mg was added to a separate set of tubes, with the volume adjusted to 3.0 mL.
-
Subsequently, 500 μL of Folin-Ciocalteu (FC) reagent, prepared as an equal part mixture with water, was added to each set of tubes containing the sample, blank, and standards.
-
After 2 min of vortexing, 2 mL of 20% w/v Na2CO3 solution was added to each tube. The tubes were then subjected to a 1-h incubation at room temperature, allowing for the development of color.
-
Absorbance readings were recorded at 650 nm against a blank using a spectrophotometer. Total phenolic content was expressed as GAE g/100 g (gallic acid equivalence per 100 g) and quantified using the gallic acid standard curve.
Spectroscopic analysis and obtaining training and validation sets
The dried Perilla seeds were stabilized at room temperature (25 °C) for 6 h to standardize temperature and moisture levels, as variations in these factors can significantly influence the absorbance and reflectance of NIR spectra. Before scanning and at 30-min intervals thereafter, the NIR spectrometer was calibrated by scanning a reference tile (100% white) to ensure accurate measurements. Approximately 4–5 g of the Perilla seeds were subjected to scanning using the FOSS NIRS 6500 spectrometer, which was equipped with Win ISI Project Manager Software version 1.50, to acquire reflectance spectra. The samples were loaded into a circular ring cup with a quartz window (3.8 cm in diameter and 1 cm in thickness) for spectral acquisition. Each spectrum represented an average of 32 scans across the spectral range of 400–2500 nm and was recorded as log (1/R), where R denotes relative reflectance, at 2 nm intervals. All the 90 Perilla genotypes were used to estimate moisture, ash, protein, TSS, and total phenols in seeds. The dataset was carefully divided into a calibration/training set, comprising 60 samples, and an external validation/testing set containing 30 samples. The categorization into these sets was performed by considering the variability in the biochemical parameters. Using Excel, the values were sorted to ensure that both sets exhibited nearly equal variability and comparable minimum and maximum values to facilitate robust model development and validation.
Calibration of MPLS- based model using WinISI
Following the acquisition of laboratory/reference values and spectral data, a series of mathematical procedures were implemented, including Modified Partial Least Squares (MPLS) regression with cross-validation. Techniques such as Standard Normal Variate (SNV) and Detrending (DT) were employed for scatter correction and preprocessing of spectral data, aimed at mitigating particle size effects and variations in light path length. Spectral derivatives were calculated to address overlapping absorption bands and baseline shift effects, thereby enhancing the accuracy of the analysis. NIRS calibrations for the spectral region spanning from 400 to 2500 nm were developed through iterative refinement, incorporating various mathematical treatments. These treatments involved derivatives, gap, and smoothing with combinations such as “2,4,4,1”, “2,4,6,1”, “2,6,6,1”, “3,4,4,1”, “3,4,6,1”, among others, to optimize predictive accuracy. For instance, in the combination “2,4,4,1”, “2” signifies the second derivative, effectively addressing overlapping absorption bands and baseline shifts. “4” denotes the gap, indicating the inclusion of six data points calculated by the second derivative. Additionally, “4” and “1” represent the number of data points in the first and second smoothing processes, respectively. To mitigate overfitting and ensure robust model performance, cross-validation was conducted under SNV and detrend scatter correction. Statistical parameters such as range, standard deviation (SD), standard error of calibration (SEC), and coefficient of determination in internal validation (RSQ internal) were assessed using Win ISI Project Manager Software version 1.50. Lower SEC and higher RSQ values were indicative of superior models. Further evaluation included the determination of standard error of cross-validation SEC (V) and 1 minus variance ratio (1-VR) for error and cross-validation assessment, respectively. Mathematical processing treatments were iteratively refined through trial and error to minimize SEC (V) and maximize 1-VR during cross-validation, thereby enhancing the predictive accuracy and reliability of the developed models.
Development of DL-based model
Considering the accuracy achieved in numerous studies related to the estimation of various variables from NIR data using deep learning-based models [7, 27, 30, 40, 44], a 1D-CNN was developed in the present study for estimating biochemical traits, namely moisture, ash, protein, phenols, and TSS in Perilla seeds. The results of the 1D-CNN were compared against the results obtained using models developed with WinISI software. The model architecture (Fig. 1) comprised six convolutional blocks stacked sequentially. Each block consisted of a 1D convolutional layer with an increasing number of filters as the model depth increased. A filter size of 1 × 3 was used in convolutional layers. Batch normalization layers were placed within each block to stabilize the learning process by mitigating internal covariate shifts [16]. A max-pooling layer (stride = 2) was inserted into each convolutional block to decrease the feature size, thus reducing the computational complexity of models [13]. The extracted features from the final convolutional block were then fed into a dense layer network. The first dense layer with 120 neurons acted as a bottleneck, compressing the feature representation obtained from the flattened layer while retaining salient information. The subsequent dense layer with 50 neurons further refined the extracted features to learn complex patterns. Finally, the single-neuron output layer with a linear activation function estimated the quantity of biochemical traits. To introduce non-linearity in the model for mapping complex relationships within the extracted feature [20], all trainable layers except the output layers utilized the ReLU activation function [1]. The final layer, designed for regression, consisted of a linear activation function [33]. Additionally, a dropout layer with a 0.3 dropout ratio was implemented into the model to prevent overfitting and improve its generalizability [36].

Constructed 1-D CNN model for NIRS-based predictive modelling in Perilla
Training of DL-based model
The input to the constructed 1D CNN model was raw spectral data, while the output was the estimated quantity of each biochemical trait. Scaling of input and output data is a common practice for NIR data before using it in deep learning-based models [15, 25]. Thus, in the present study, min–max scaling [21] of raw spectral data was carried out, dividing it into training, validation, and testing data with a ratio of 60:20:20, respectively. The Adam optimizer [18] with a learning rate of 0.001 was utilized to update the weights during training. Mean absolute error (MAE) was used as the accuracy metric, while mean squared error (MSE) served as the cost function during model training. The model was trained for 350 epochs with a batch size of seven instances. The performance of the developed model was evaluated using metrics such as R2, bias, RPD, and SEP.
Validation or performance evaluation of the developed models
The performance evaluation of the calibrated/trained models was conducted using comprehensive global statistical metrics, including RSQexternal (Coefficient of determination for external validation), bias, SEP(C) (Corrected standard error of prediction), and RPD (Residual predicted deviation). These metrics offer a thorough assessment of the predictive accuracy and reliability of the models [41]. To ensure the authenticity of the developed models, both MPLS and DL-based, individual confirmation was sought through an external sample validation set. This step is crucial as cross-validation alone may be insufficient for verifying the model’s efficacy. The evaluation of prediction accuracy for the external validation set involved assessing RSQexternal, bias (indicating the systematic difference between the reference and predicted values, thereby reflecting the strength of the correlation between the two), and SEP(C). To gauge the accuracy of the developed models, the residual prediction deviation (RPD) was employed. RPD is calculated as the ratio of the standard deviation (SD) of the reference values for samples in the validation set to the SEP corrected for bias [6, 38]. This comprehensive approach ensures a robust validation process for the developed models, providing confidence in their ability to accurately predict the biochemical traits of interest in the germplasm.
here.
RSQinternal/external: Coefficient of determination for calibration (internal) and validation (external) sample set.
Ycalculated: The actual evaluated value of the parameter.
Ypredicted: The predicted value of the parameter through a regression line.
Ymean: Arithmetic mean of y values.
n: Number of spectra.
xi: Value of the one observation.
xmean: Mean value of all observations.
Statistical analysis
For the MPLS-based model, Win ISI III Project Manager software version 1.50 was utilized for calibrations and predictions, incorporating various mathematical treatments for both spectral and analyzed data. The coefficient of determination (RSQ internal/external) for the biochemical parameters in reference versus predicted values was independently confirmed using MS Excel. To assess the prediction accuracy of all developed models, a paired t-test was conducted at a 95% confidence interval utilizing IBM SPSS Statistics 21. The results were presented in the form of standard error of the mean, standard deviation (SD), t-value, and p-values. Furthermore, a stringent parallel reliability (unbiased) test and correlation analysis between reference and predicted values of biochemical traits were conducted using IBM SPSS Statistics 21.
Experimental design and quality control
In the experiment, a completely randomized design (CRD) was adopted, ensuring that both the spectral acquisition and evaluation of biochemical parameters were randomly assigned to each sample unit. This approach guaranteed that every sample had an equal probability of receiving any treatment. To validate spectral accuracy, each sample was scanned twice, thereby minimizing spectral error. Subsequent data analysis utilized the average spectrum of each sample to ensure consistency. For robustness and replicability, all biochemical parameters were estimated in triplicates. The mean values obtained from these replicates were utilized for both the calibration and validation sets, enhancing the accuracy of the results. The overall methodology employed in the present research is illustrated in Fig. 2, summarizing the sequential steps followed in the experiment, from sample preparation and spectral acquisition to biochemical parameter estimation and data analysis.

Overall illustration of the experimental procedure. A Perilla (Perilla frutescens L.) seed samples; B Samples loaded into Near infrared spectrometer (NIRS); C Energy transition of sample molecules: Under typical circumstances, molecules within a sample maintain a ground state (n = 0), where they exhibit minimal energy vibration. However, upon exposure to Near-Infrared (NIR) light, an energy shift occurs, causing the molecules to transition from the ground state to excited states (n > 0). The fundamental vibration frequency corresponds to the energy transition from the ground state (0) to the first excited state (1). Furthermore, overtone vibration frequencies signify the transition of energy from the ground state (0) to higher states (n > 1). For instance, the transition from level 0 to 2 is termed as the first overtone, and subsequent transitions follow suit. Similarly, the transition from level 0 to 3 is referred to as the second overtone, and this pattern persists; D internal components of a typical NIRS. The spectra were obtained by loading the homogenized sample in a circular ring cup with a quartz window (3.8 cm in diameter and 1 cm in thickness). Here the NIR signals are detected by the detector; E A typical NIRS spectrum indicating the peaks; F Wet chemistry analysis of Perilla samples for nutritionally relevant biochemical parameters like moisture, ash, protein, total soluble sugars, and phenols; G Calibration of model using modified partial least square regression. This was followed by the application of various mathematical algorithms for scatter correction and preprocessing of the spectral data including the Standard Normal Variate (SNV) and Detrending (DT); H Construction of a 1-D CNN model. I Representation of the prediction accuracy by scatter plot between the reference and predicted values
Results and discussion
Patterns of biochemical composition and acquisition and analysis of NIRS spectra
An overview of the statistical analysis of biochemical parameters, namely moisture, ash, protein, total soluble sugars (TSS), and total phenols, observed across 90 diverse Perilla germplasm samples is presented in Table 1. The descriptive statistics include mean values, standard deviations (SDs), and ranges to estimate variability within the dataset. Moisture content, with a mean of 6.16% and an SD of 1.99, showed significant variability, ranging from 0.39% to 11.66%. Ash content, with a mean of 4.13% and an SD of 0.99, demonstrated moderate variability. Protein content, with a maximum value of 23.12% and a mean of 17.73%, exhibited notable diversity across the germplasm. This compositional pattern of moisture, ash, and protein supports an earlier study by Sargi et al. [31] wherein they observed moisture (6.02 ± 0.12%), ash (3.33 ± 0.02%), and crude protein (25.38 ± 0.10%). Total soluble sugars (TSS), with a mean of 1.58%, showed moderate variability across the samples. Conversely, the total phenol content ranged from 0.03% to 0.87%, indicating relatively small variation in concentration among the samples. Overall, these findings highlight enriched diversity in nutritional traits across the diverse Perilla germplasm. The distribution of moisture, ash, protein, TSS, and total phenol content (expressed in percentages) across diverse Perilla germplasm from the NEHR of India is depicted in Fig. 3.

Distribution of moisture, ash, protein, TSS, and total phenols content (in %) in diverse Perilla germplasm from NEHR of India. A comparison between reference and predicted values
The collective near-infrared (NIR) spectra spanning the wavelength range of 400–2490 nm (corresponding to 25,000–4016 cm⁻1) for seeds sourced from a diverse Perilla germplasm collection in the NEHR of India are presented in Fig. 4. Distinguishing NIR regions visually becomes difficult due to the prevalence of highly overlapping and broad combination bands arising from fundamental vibrations [6]. Additionally, consideration of matrix effects, particularly for biological materials like Perilla seeds, is imperative to ensure model applicability across diverse matrices, posing additional challenges due to the complex food matrix interactions, especially attributable to the high oil content (~ 52.00%) and intricate bonding between protein, sugars, phenols, and fatty acids.

A combined plot of the reflectance of entire perilla germplasm (90 samples)
The overlapping absorption peaks primarily correspond to combinations and overtones of vibrational modes associated with N–H, O–H, and C–H bonds relevant to proteins, fatty acids, and carbohydrates, respectively. Notably, the complexities arising from these overlapping absorption bands impede the elucidation of relationships between calibrated traits and their associated wavelengths, complicating the isolation of features relevant to individual parameters [3]. For instance, the broad O–H bonds around 2100 nm can obscure variations in energy resulting from protein amide bond absorption [10].
It has been observed that peaks within the spectral region ranging from 4500 to 5000 cm⁻1 are attributed to combinations of C–O and N–H stretching, indicative of protein content [29]. Furthermore, the region spanning 7000–6800 cm⁻1, featuring a wide peak, corresponds to the O–H stretch first overtone of hydroxyl phenol groups and C–H combinations of aromatic compounds. Additionally, the peak near 5200 cm⁻1 is associated with O–H bending/stretching of polysaccharides, aligning with water absorption, while peaks near 4800 cm⁻1 may arise from asymmetric C–O–O stretches, signifying the third overtone of polysaccharides [43]. Similar peaks identifying these specific functional groups have been reported by [5, 37, 38].
Furthermore, it has been observed that variations in sample composition, moisture content, and particle size can significantly impact prediction accuracy, necessitating a uniform seed sample size. The reliability of predictions is also contingent upon the quality of the NIR instrument, thus requiring regular calibration updates to account for changes in instrument performance over time. Additionally, non-linear responses of certain chemical constituents in the NIR region pose a challenge, necessitating the utilization of advanced modeling techniques. Hence, a 1D Convolutional Neural Network (CNN) in conjunction with Modified Partial Least Squares (MPLS) was employed for comparison and to enhance prediction accuracy.
Pre-processing and calibration of MPLS-based model using WinISI
In this study, appropriate measures were undertaken to ensure the impartial division of subsets and maintain consistency. Biochemical parameter values were arranged in ascending order to facilitate unbiased subset divisions. The calibration and validation sets were carefully selected to achieve a balanced distribution of minimum, median, and maximum values in both sets. Several regression algorithms, including Partial Least Squares (PLS), Modified Partial Least Squares (MPLS), and Principal Component Regression (PCR), were employed. Notably, MPLS demonstrated superior accuracy and stability compared to standard PLS regression. MPLS has emerged as the preferred choice in various chemometric applications due to its ability to address multicollinearity, enhance robustness against outliers, and optimize spectral data treatment. The method involves computing and standardizing residuals at each wavelength, effectively minimizing the impact of irrelevant spectroscopic variations. By maximizing the capture of variation in spectroscopic data through the incorporation of reference values, MPLS mitigates the influence of extraneous factors, thereby augmenting calibration modeling accuracy [12]. This balance between predictive power and model complexity ensures reliability, particularly in small datasets or challenging conditions, aligning with the findings of previous studies [17, 28, 38].
To address complexities arising from alterations in light scattering and path length variations, spectral pre-processing techniques were employed. The Standard Normal Variate (SNV) method effectively diminishes the multiplicative effects of particle size and scattering by centering each spectrum around zero, thus reducing differences in global signal intensities [24]. Additionally, the Detrend (DT) method was utilized to correct baseline shifts and enhance the determination of signal attributes related to parameter concentration [4]. This involved fitting a polynomial function to all data points, effectively removing specific trending variations and large background interference [11]. The combined use of SNV and DT circumvents curvilinearity and noise in the NIRS signal baseline, ensuring effective pre-processing of spectral data.
During the model development phase, multiple mathematical treatments were explored through permutations and combinations. Ultimately, calibration equations were selected based on achieving the highest 1-VR and RSQinternal values and the lowest standard error of cross-validation, SEC(V), among all mathematical treatments. Derivatives 2 and 3 were utilized to eliminate persistent background signals and improve visual resolution, while Gap 4 and 6 and smoothing techniques (S1-4 and 6, S2-1) were applied to reduce noise caused by erratic high-frequency perturbations. Derivatives and mathematical transformations act as high-pass filters, isolating and highlighting subtle peaks in the data that may be challenging to discern directly from the original spectrum. Essentially, they aid in the identification and understanding of weak peaks in the presence of low-frequency changes in baseline and background signals.
Validation of the NIRS-based prediction models
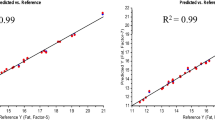
To validate the developed models externally using both WinISI and deep learning techniques, a validation set comprising 40.0% of samples was reserved and designated as the validation set. The estimation of the five biochemical parameters for this set was conducted using the same methods as employed in the calibration set. Statistical metrics such as RSQexternal, slope, bias, RPD, and SEP(C) were used to quantify the accuracy and precision of the developed models. A comparative analysis of the metrics used for validation for five key biochemical traits employing both WinISI and 1D CNN models is presented in Table 2. Scatter plots of reference and predicted values for moisture, ash, protein, TSS, and total phenol contents (%) in perilla seeds are depicted in Fig. 5 & 6.

Scatter plots of reference and predicted values for moisture and ash content (%) in perilla seeds

Scatter plots of reference and predicted values for protein, TSS, and total phenols content (%) in perilla seeds
The coefficient of determination (R-squared or RSQ) serves to estimate the proximity of the fitted regression line to the actual data, comparing the sum of squared differences between the predicted and reference values to the sum of squared differences between the observed values and their mean. A higher R-squared value, nearing 1, indicates greater accuracy in how the model aligns with the actual data values. Across all traits (except protein), both WinISI and 1D CNN consistently demonstrated comparable RSQ values (approximately 0.8), suggesting a better fit between the predicted and reference values. Interestingly, in the case of proteins, the RSQ value was comparatively higher with 1D CNN (RSQ = 0.92) compared to that of WinISI (RSQ = 0.82), indicating its superiority in predicting the protein content.
The slope signifies how predicted values change in response to a one-unit shift in reference values. An ideal slope is 1, and values approaching this indicate model accuracy. Across the traits, the slope values varied for both models, indicating the degree of linearity in the predictions. Interestingly, for total phenols and protein, 1D CNN demonstrated a slope of 0.9, suggesting a robust linear relationship, while WinISI exhibited a slope of 1.00 for total phenols indicating a perfectly linear prediction, and 0.79 for protein indicating nearly perfect prediction. Bias, assessed through the mean squared difference between predicted and reference values, serves as a crucial metric for evaluating the consistency between reference and predicted values, offering insights into model accuracy. An ideal scenario is characterized by a bias value of zero, indicating perfect alignment between the reference and predicted values. Positive bias values signify model overestimation, while negative values suggest model underestimation of the evaluated parameter. For ash, protein, and TSS, the 1D CNN model consistently exhibited lower bias values (0.08, 0.12, and 0.05 respectively) compared to WinISI (− 0.09, 0.17, and 0.16), indicative of reduced systematic deviation in predictions. For total phenols, both WinISI and 1D CNN model demonstrated lower bias value (bias = 0.01), suggesting a highly diminished tendency for systematic errors. These findings collectively highlight the specific potential of both the models to provide more accurate and less biased predictions across diverse biochemical traits.
The convolutional layers of 1D CNNs are designed to identify hidden hierarchical features in the input data, allowing them to discern complex patterns that might be challenging for traditional methods like WinISI. Moreover, the deep learning approach inherently handles non-linear relationships effectively, which can be crucial in the case of complex biochemical compositions like proteins. These features of 1D CNN may elucidate the observed higher RSQ value, signifying its superiority in accurately predicting protein content compared to WinISI. In various crops such as pearl millet, rice, and cowpea, comparable RSQ values of 0.929, 0.917, 0.894, and 0.903, respectively, were reported in their NIRS-based predictions for protein content [17, 28, 38].
Furthermore, while it is commonly believed that deep learning requires large datasets, several studies have demonstrated its effectiveness even with smaller/medium datasets, provided the data is of high quality and properly pre-processed. For instance, 207 samples were used for predicting sensory traits in sweet potatoes using machine learning methods and near-infrared spectroscopy [26]. Another study utilised, 192 samples in a deep-learning-based regression model and hyperspectral imaging to detect nitrogen concentration in oilseed rape leaves [42]. In our case, the sample was sufficiently diverse, and even with medium-sized data, we were having having 4200 dependent variables in the form of NIR spectra data and deep learning has given better results in validation than MPLS, signifying its utility.
Corrected standard error of prediction (SEP(C)) is calculated using the square root of the mean squared difference between the predicted and reference values. A smaller SEP indicates that the predicted values are closer to the calculated values on average. Residual predicted deviation (RPD) expresses the relationship between the variability in the observed data (measured by the standard deviation) and the average magnitude of errors in predictions (measured by the corrected standard error of prediction). This provides a metric to authenticate the model’s validity, which is more precise than SEP(C) and can be easily compared across various model validation studies. A higher RPD value suggests that the variability in the observed values is relatively larger compared to the average prediction error, indicating better predictive performance. A model with RPD less than 1.5 is considered unreliable, while values between 1.5 and 2.0 indicate the ability of the model to distinguish between high and low values. RPD values between 2.0 and 2.5 suggest an approximate quantitative prediction, while those in the range of 2.5 to 3.0 signify a good-quality prediction. An RPD exceeding 3.0 is indicative of an excellent prediction. For protein, comparable RPD values were observed using WinISI (2.24 by WinISI and 2.36 by 1D CNN), indicating nearly similar quantitative predictive capacity for both models. However, in the case of TSS, 1D CNN demonstrated an excellent predictive capacity (RPD = 3.85) compared to WinISI (RPD = 1.99), which was only able to distinguish between high and low values. Remarkably, 1D CNN exhibited an exceptional RPD of 8.47 in predicting total phenols compared to WinISI (RPD = 2.05), indicating its outstanding ability to provide reliable predictions for total phenols. In contrast to prior studies employing NIRS-based prediction models in various crops, our observations reveal that the 1D CNN exhibited exceptionally higher RPD values, particularly for TSS (3.67) and phenols (7.97). This highlights the superior predictive potential of the 1D CNN model over WinISI, specifically in the estimation of these traits. Understanding the complex relationships between calibrated traits and their associated wavelengths can be challenging, primarily due to the overlap in NIR band vibrations linked to different traits. An additional complicating factor arises when traits are present in extremely low concentrations (for instance, TSS and total phenols in Perilla seeds). These particular traits typically exhibit regression coefficients and NIR absorption band numbers at lower wavelengths. Our findings suggest that utilizing a 1D CNN yields superior predictions, demonstrating lower bias and SEP(C), and excellently higher RPD, thus excels in predicting traits present in minimal amounts, such as TSS and total phenols, outperforming the conventional WinISI method.
Comparison of WinISI and 1 D CNN-based NIRS prediction models
The comparative assessment of WinISI and 1D CNN models for predicting key biochemical traits revealed distinct performance characteristics. Regarding moisture content, both models demonstrated commendable predictive capabilities, with comparable RSQ values (0.83 for WinISI and 0.86 for 1D CNN). However, WinISI exhibited a remarkable advantage in terms of RPD, yielding a superior value of 2.22 compared to 1D CNN’s 1.61. This highlights WinISI’s enhanced ability to predict moisture content relative to the inherent dataset variability. For ash content prediction, both models exhibited robust accuracy, as evidenced by high RSQ values (0.83), but 1D CNN depicted better precision with higher RPD (2.63) compared to WinISI (2.39) (Fig. 7). In predicting protein content, 1D CNN depicted higher RSQ (0.92) than WinISI (0.82), accompanied by nearly comparable RPD values (2.24 for WinISI and 2.36 for 1D CNN). However, WinISI exhibited enhanced precision, reflected in a lower SEP of 0.48 compared to 1D CNN’s 0.87. TSS predictions indicated equitable performance from both models with respect to identical RSQ values of approximately 0.7; however, 1D CNN yielded superior precision with significantly higher RPD (3.85), lower SEP(C) (0.16), compared to that of WinISI (RPD = 1.99, SEP(C) = 0.43), suggesting a subtle reduction in precision. Of particular note is the prediction of total phenols, where the 1D CNN model surpassed WinISI with a significantly higher RPD of 8.47 compared to WinISI’s 2.05. Although the SEP(C) values for total phenols were small for both models, they indicate marginally better precision for 1D CNN (0.02) compared to WinISI (0.06). In summary, while both models exhibited strong predictive capabilities, WinISI excelled in predicting moisture with slightly better precision. However, for ash, protein, TSS, and total phenol prediction, the 1D CNN model emerged as more effective due to the better RPD, emphasizing the importance of selecting models based on the specific biochemical trait of interest. 1-D CNNs can automatically capture complex local patterns within input spectral data by applying convolutional filters, thus demonstrating higher efficacy in prediction [30, 34]. Overall, the comprehensive comparative analysis offers valuable insights into the performance of WinISI and 1D CNN across various biochemical traits, thereby informing the selection, refinement, and application of predictive models in analytical research contexts.

Comparison of WinISI and deep learning models with respect to RSQexternal, bias, SEP(C), and RPD values of biochemical traits
Statistical analysis of the developed models
To determine the comparability of mean values of a dependent variable with both reference and predicted values for estimated biochemical parameters, a paired t-test with a 95% confidence interval was executed. The resulting p-value exceeded the significance threshold of 0.05, suggesting the robust accuracy and reliability of the models, as indicated in Table 3. Specifically, for moisture, ash, protein, TSS, and phenols, the p-values were 0.145, 0.233, 0.567, 0.061, and 0.256, respectively, employing the MPLS method using WinISI, and 0.299, 0.236, 0.060, 0.768, and 0.260 employing 1D CNN utilizing deep learning. These findings highlight a lack of statistically significant differences in means between the NIRS-based prediction method and the WinISI and deep learning approaches.
Furthermore, correlation analyses between reference and predicted value datasets revealed noteworthy associations. Particularly high correlation coefficients were observed for protein content, r = 0.91 with WinISI and an even higher 0.96 with the deep learning approach. Similarly robust correlations were observed for moisture, ash, and phenolic content (r = ~ 0.91 with both WinISI and deep learning). A slightly diminished yet statistically significant correlation was observed for TSS (r = 0.88 with both WinISI and deep learning) (Table 4). These correlation findings highlight the efficacy of both WinISI and deep learning methodologies in predicting biochemical parameters, emphasizing their capacity to determine associations between reference and predicted values for these traits.
Additionally, strict parallel analysis was conducted to determine differences in the means and standard deviations of the two datasets (reference vs predicted values using WinISI and deep learning). The findings unveiled a consensus in results, signifying a high level of concurrence and consistency, thereby affirming the robustness of the obtained reliability scores. For moisture, ash, and phenols content, both WinISI and deep learning exhibited high reliability (unbiased) (0.95). Protein content predictions also indicated high reliability (unbiased) of 0.95 and 0.98 using WinISI and deep learning, respectively.
Conclusions
Ensuring both nutritional and environmental stability necessitates incorporating neglected or underutilized crops into conventional agricultural practices. In this context, Perilla emerges as a promising candidate due to its abundant nutritional advantages. We addressed the critical need for a rapid, cost-effective, and less labor-intensive germplasm screening method in Perilla, utilizing Near-Infrared Spectroscopy (NIRS). Developing Partial Least Squares (PLS) and 1D Convolutional Neural Network (CNN)-based NIRS prediction models, employing WinISI and deep learning frameworks respectively, marked a significant advancement in high-throughput screening of Perilla germplasm. The calibration process, employing mathematical treatments such as permutations and combinations, led to identifying optimal equations for each biochemical trait. The selection of specific equations, such as “2,6,6,1” for moisture, “3,4,4,1” for ash and total soluble solids (TSS), “3,4,6,1” for protein, and “2,4,6,1” for phenols, underscores the precision achieved in the prediction models. External validation, utilizing metrics such as RSQexternal, RPD, slope, bias, and SEP(C), underlines the robust predictive capabilities of both WinISI and 1D CNN models across various biochemical traits. While WinISI excelled in moisture content with better precision (R2: 0.86, RPD: 2.22), the 1D CNN model significantly outperformed WinISI in ash (R2: 0.83, RPD: 2.63), protein (R2: 0.92, RPD: 2.36), TSS (R2: 0.78, RPD: 3.85), and total phenol prediction (R2: 0.82, RPD: 8.47). This highlights the importance of model selection for specific traits in analytical applications. The resultant models provide a rapid screening tool for Perilla germplasm, aiding in identifying nutritionally dense genotypes and guiding targeted breeding efforts. This is the first report on comparative mPLS and DL-based modeling using NIRS data in predicting key biochemical components in Perilla.
Data availability
Data available on request from the authors.
References
A. F. Agarap, Deep learning using rectified linear units (ReLU) (arXiv:1803.08375) (2019). Preprint at https://doi.org/10.48550/arXiv.1803.08375
C. Aochen, A. Kumar, S. Jaiswal, K. Puro, P.W. Shimray, S. Hajong, R.H.C. Sangma, S. Aochen, B. Iangrai, B. Bhattacharjee, L. Jamir, T. Angami, A. Pattanayak, V.K. Mishra, Perilla frutescens L.: a dynamic food crop worthy of future challenges. Front. Nutr. (2023). https://doi.org/10.3389/fnut.2023.1130927
T.B. Bagchi, S. Sharma, K. Chattopadhyay, Development of NIRS models to predict protein and amylose content of brown rice and proximate compositions of rice bran. Food Chem. 191, 21–27 (2016). https://doi.org/10.1016/j.foodchem.2015.05.038
J.M. Cáceres-Nevado, A. Garrido-Varo, E. De Pedro-Sanz, D. Tejerina-Barrado, D.C. Pérez-Marín, Non-destructive Near Infrared Spectroscopy for the labelling of frozen Iberian pork loins. Meat Sci. 175, 108440 (2021). https://doi.org/10.1016/j.meatsci.2021.108440
J. Chen, X. Ren, Q. Zhang, X. Diao, Q. Shen, Determination of protein, total carbohydrates and crude fat contents of foxtail millet using effective wavelengths in NIR spectroscopy. J. Cereal Sci. 58(2), 241–247 (2013). https://doi.org/10.1016/j.jcs.2013.07.002
D. Cozzolino, Foodomics and infrared spectroscopy: from compounds to functionality. Curr. Opin. Food Sci. 4, 39–43 (2015). https://doi.org/10.1016/j.cofs.2015.05.003
S. Devianti, R. Bulan, A. Sitorus, Vis-NIR spectra combined with machine learning for predicting soil nutrients in cropland from Aceh Province, Indonesia. Case Stud Chem Environ Eng 6, 100268 (2022). https://doi.org/10.1016/j.cscee.2022.100268
A. Dhyani, R. Chopra, M. Garg, A review on nutritional value, functional properties and pharmacological application of Perilla (Perilla Frutescens L.). Biomed. Pharmacol. J. 12(2), 649–660 (2019)
J.T. Diaz, E.A. Foegeding, L. Stapleton, C. Kay, M. Iorizzo, M.G. Ferruzzi, M.A. Lila, Foaming and sensory characteristics of protein-polyphenol particles in a food matrix. Food Hydrocolloids 123, 107148 (2022). https://doi.org/10.1016/j.foodhyd.2021.107148
C. Egesel, F. Kahriman, Determination of quality parameters in maize grain by NIR reflectance spectroscopy. J. Agric. Sci. 18(1), 1 (2012)
C.A. Esquerre, E.M. Achata, M. García-Vaquero, Z. Zhang, B.K. Tiwari, C.P. O’Donnell, Use of an NIR MEMS spectrophotometer and visible/NIR hyperspectral imaging systems to predict quality parameters of treated ground peppercorns. LWT 131, 109761 (2020). https://doi.org/10.1016/j.lwt.2020.109761
R. Font, M. del Río, J.M. Fernández-Martínez, A. de Haro-Bailón, Use of Near-Infrared Spectroscopy for screening the individual and total glucosinolate contents in Indian Mustard seed (Brassica juncea L. Czern. & Coss.). J Agric Food Chem 52(11), 3563–3569 (2004). https://doi.org/10.1021/jf0307649
H. Gholamalinezhad, H. Khosravi, Pooling methods in deep neural networks, a review (2020). Preprint at https://doi.org/10.48550/ARXIV.2009.07485
J. Hansen, I. Møller, Percolation of starch and soluble carbohydrates from plant tissue for quantitative determination with anthrone. Anal. Biochem. 68(1), 87–94 (1975). https://doi.org/10.1016/0003-2697(75)90682-X
R. Helin, U.G. Indahl, O. Tomic, K.H. Liland, On the possible benefits of deep learning for spectral preprocessing. J. Chemom. 36(2), e3374 (2022). https://doi.org/10.1002/cem.3374
S. Ioffe, C. Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv:1502.03167 [Cs] (2015). Preprint at http://arxiv.org/abs/1502.03167
R. John, R. Bhardwaj, C. Jeyaseelan, H. Bollinedi, N. Singh, G.D. Harish, R. Singh, D.J. Nath, M. Arya, D. Sharma, S. Singh, K.J. John, M. Latha, J.C. Rana, S.P. Ahlawat, A. Kumar, Germplasm variability-assisted near infrared reflectance spectroscopy chemometrics to develop multi-trait robust prediction models in rice. Frontiers in Nutrition 2022, 946255 (2022). https://doi.org/10.3389/fnut.2022.946255
D. P. Kingma, J. Ba, Adam: a method for stochastic optimization. arXiv:1412.6980 [Cs] (2017). Prepint at http://arxiv.org/abs/1412.6980
S. Kongkeaw, S. Riebroy, M. Chaijan, Comparative studies on chemical composition, phenolic compounds and antioxidant activities of brown and white Perilla (Perilla frutescens) seeds. Chiang Mai 42(4), 896–906 (2015)
N. Kulathunga, N.R. Ranasinghe, D. Vrinceanu, Z. Kinsman, L. Huang, Y. Wang, Effects of nonlinearity and network architecture on the performance of supervised neural networks. Algorithms 14(2), 51 (2021). https://doi.org/10.3390/a14020051
M.G. Lanjewar, P.P. Morajkar, J.S. Parab, Portable system to detect starch adulteration in turmeric using NIR spectroscopy. Food Control 155, 110095 (2024). https://doi.org/10.1016/j.foodcont.2023.110095
T. Longvah, Y.G. Deosthale, P. Uday Kumar, Nutritional and short term toxicological evaluation of Perilla seed oil. Food Chem. 70(1), 13–16 (2000). https://doi.org/10.1016/S0308-8146(99)00263-0
R.E. Masithoh, S. Lohumi, W.-S. Yoon, H.Z. Amanah, B.-K. Cho, Development of multi-product calibration models of various root and tuber powders by fourier transform near infra-red (FT-NIR) spectroscopy for the quantification of polysaccharide contents. Heliyon (2020). https://doi.org/10.1016/j.heliyon.2020.e05099
P. Mishra, S. Lohumi, Improved prediction of protein content in wheat kernels with a fusion of scatter correction methods in NIR data modelling. Biosys. Eng. 203, 93–97 (2021). https://doi.org/10.1016/j.biosystemseng.2021.01.003
P. Mishra, D. Passos, F. Marini, J. Xu, J.M. Amigo, A.A. Gowen, J.J. Jansen, A. Biancolillo, J.M. Roger, D.N. Rutledge, A. Nordon, Deep learning for near-infrared spectral data modelling: hypes and benefits. TrAC, Trends Anal. Chem. 157, 116804 (2022). https://doi.org/10.1016/j.trac.2022.116804
J.S. Nantongo, E. Serunkuma, G. Burgos, M. Nakitto, F. Davrieux, R. Ssali, Machine learning methods in near infrared spectroscopy for predicting sensory traits in sweetpotatoes. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 318, 124406 (2024). https://doi.org/10.1016/j.saa.2024.124406
J. Padarian, B. Minasny, A.B. McBratney, Using deep learning to predict soil properties from regional spectral data. Geoderma Reg. 16, e00198 (2019). https://doi.org/10.1016/j.geodrs.2018.e00198
S.R. Padhi, A. Bartwal, R. John, K. Tripathi, K. Gupta, D.P. Wankhede, G.P. Mishra, S. Kumar, S. Archak, R. Bhardwaj, Evaluation and multivariate analysis of cowpea [Vigna unguiculata (L.) Walp] germplasm for selected nutrients—mining for nutri-dense accessions. Front. Sustain. Food Syst. (2022). https://doi.org/10.3389/fsufs.2022.888041
M. Plans, J. Simó, F. Casañas, J. Sabaté, L. Rodriguez-Saona, Characterization of common beans (Phaseolus vulgaris L.) by infrared spectroscopy: comparison of MIR, FT-NIR and dispersive NIR using portable and benchtop instruments. Food Res. Int. 54(2), 1643–1651 (2013). https://doi.org/10.1016/j.foodres.2013.09.003
X. Sang, R. Zhou, Y. Li, S. Xiong, One-dimensional deep convolutional neural network for mineral classification from raman spectroscopy. Neural Process. Lett. 54(1), 677–690 (2022). https://doi.org/10.1007/s11063-021-10652-1
S.C. Sargi, B.C. Silva, H.M.C. Santos, P.F. Montanher, J.S. Boeing, O.O. Santos Júnior, N.E. Souza, J.V. Visentainer, Antioxidant capacity and chemical composition in seeds rich in omega-3: Chia, flax, and perilla. Food Sci. Technol. 33, 541–548 (2013). https://doi.org/10.1590/S0101-20612013005000057
S. Sarkar, A. Sunil Menon, T. Gopalakrishnan, A.K. Kakelli, Convolutional neural network based selective amplification (CNN-SA) model to enhance image quality for efficient fire detection. Int. J. Image Graph. Signal Process. 13(5), 51–59 (2021). https://doi.org/10.5815/ijigsp.2021.05.05
H. Selim, Determinants of house prices in Turkey: Hedonic regression versus artificial neural network. Expert Syst. Appl. 36(2, Part 2), 2843–2852 (2009). https://doi.org/10.1016/j.eswa.2008.01.044
Z. Shen, R.A. Viscarra Rossel, Automated spectroscopic modelling with optimised convolutional neural networks. Sci. Rep. 11(1), 1 (2021). https://doi.org/10.1038/s41598-020-80486-9
A. Sluiter, B. Hames, R. Ruiz, C. Scarlata, J. Sluiter, D. Templeton, D. L. A. P. Crocker, Determination of structural carbohydrates and lignin in biomass. Laboratory Analytical Procedure (LAP) (Technical Report NREL/TP-510-42622) (2008)
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–1958 (2014)
W. Tian, G. Chen, Y. Gui, G. Zhang, Y. Li, Rapid quantification of total phenolics and ferulic acid in whole wheat using UV–Vis spectrophotometry. Food Control 123, 107691 (2021). https://doi.org/10.1016/j.foodcont.2020.107691
M. Tomar, R. Bhardwaj, M. Kumar, S.P. Singh, V. Krishnan, R. Kansal, R. Verma, V.K. Yadav, A. Dahuja, S.P. Ahlawat, J. Chand Rana, C.T. Satyavathi, S. Praveen, A. Sachdev, Development of NIR spectroscopy based prediction models for nutritional profiling of pearl millet (Pennisetum glaucum (L.)) R.Br: a chemometrics approach. LWT 149, 111813 (2021). https://doi.org/10.1016/j.lwt.2021.111813
D. Wang, H. Li, T.-Y. Hou, Z.-J. Zhang, H.-Z. Li, Effects of conjugated interactions between Perilla seed meal proteins and different polyphenols on the structural and functional properties of proteins. Food Chem. 433, 137345 (2024). https://doi.org/10.1016/j.foodchem.2023.137345
D. Wang, F. Tian, S.X. Yang, Z. Zhu, D. Jiang, B. Cai, Improved deep CNN with parameter initialization for data analysis of near-infrared spectroscopy sensors. Sensors 20(3), 874 (2020). https://doi.org/10.3390/s20030874
P. Williams, P. Dardenne, P. Flinn, Tutorial: Items to be included in a report on a near infrared spectroscopy project. J Near Infrared Spectr. 25(2), 2 (2017). https://doi.org/10.1177/0967033517702395
X. Yu, H. Lu, Q. Liu, Deep-learning-based regression model and hyperspectral imaging for rapid detection of nitrogen concentration in oilseed rape (Brassica napus L.) leaf. Chemom. Intell. Lab. Syst. 172, 188–193 (2018). https://doi.org/10.1016/j.chemolab.2017.12.010
K. Zhang, L. Zhou, M. Brady, F. Xu, J. Yu, D. Wang, Fast analysis of high heating value and elemental compositions of sorghum biomass using near-infrared spectroscopy. Energy 118, 1353–1360 (2017). https://doi.org/10.1016/j.energy.2016.11.015
X. Zhang, T. Lin, J. Xu, X. Luo, Y. Ying, DeepSpectra: an end-to-end deep learning approach for quantitative spectral analysis. Anal. Chim. Acta 1058, 48–57 (2019). https://doi.org/10.1016/j.aca.2019.01.002
Acknowledgements
The authors express gratitude to the Directors of the ICAR Research Complex for NEH Region, Umiam, Meghalaya—793 103 (India), and ICAR- National Bureau of Plant Genetic Resources, New Delhi—110 012 (India), for providing the necessary facilities for conducting this study. Authors also acknowledge the support from All India Coordinated Network Project on Potential Crops, ICAR NEH Shillong centre for providing the necessary facilities for conducting this study.
Funding
This work has been conducted as a part of the Professional Attachment Training of the lead author at ICAR- National Bureau of Plant Genetic Resources, New Delhi—110 012 (India) and also supported by her in-house project (funded by the ICAR RC for NEH Regon, Umiam, Meghalaya, India). The work was supported by the International collaborative project” Consumption of Resilient Orphan Crops & Products for Healthier Diets” (CROPS4HD), which is co-funded by the Swiss Agency for Development and Cooperation, Global Programme Food Security (SDC GPFS), and executed in India through FiBL (Research Institute of Organic Agriculture), and Alliance of Bioversity and CIAT with ICAR- National Bureau of Plant Genetic Resources, New Delhi—110 012 (India).
Author information
Authors and Affiliations
Contributions
Simardeep Kaur: conceptualization, investigation, data curation, formal analysis, writing—original draft; Naseeb Singh: software; formal analysis, writing—review and editing; Maharishi Tomar: visualization, writing- review & editing; Amit Kumar: data curation, resources; Samarth Godara: formal analysis; Siddhant Ranjan Padhi: writing—review and editing; Binay K. Singh: project administration, supervision, writing—review and editing; Rakesh Bhardwaj: project administration, conceptualization, supervision, writing—review and editing, funding acquisition; Jai Chand Rana and Amritbir Riar: Critical review, revision and resources.
Corresponding authors
Ethics declarations
Conflict Of interest
All the authors declare no conflict of interest and state that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kaur, S., Singh, N., Tomar, M. et al. NIRS-based prediction modeling for nutritional traits in Perilla germplasm from NEH Region of India: comparative chemometric analysis using mPLS and deep learning. Food Measure 18, 9019–9035 (2024). https://doi.org/10.1007/s11694-024-02856-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11694-024-02856-5